

Data validation techniques: How to keep your data accurate, useful, and privacy-compliant
Every business handles data. Whether based on customer profiles, marketing campaign performance, or internal reporting, decisions are only as reliable as the data behind them.
This is where data validation techniques become important, because your decisions are only as good as the quality of the data informing them.

Think of data validation as a gatekeeper. Its job is to allow only useful, correct, and expected information to pass through. This job isn’t just about fixing spelling errors in a spreadsheet. It’s about maintaining trust: among departments, platforms — and most importantly — businesses and their customers.
So, why is this essential for businesses? Without a consistent data validation process, it’s nearly impossible to have correct reporting or to effectively use data for analytics and insights. Below, we’ll cover what data validation is, plus multiple techniques and best practices you can implement to keep your data in shape.
What is data validation?
Data validation is the process of ensuring that data is correct, clean, and useful before it is stored or used. Instead of fixing data after something has gone wrong, the goal of data validation is to catch problems early. Ideally, the moment data enters a system.
Data validation methods answer questions like:
- Is this value the right type, e.g. a number instead of a name?
- Does this value fall within an acceptable range, e.g. an age between 18 and 99?
- Is this field required, and if so, is it present?
Without validation, small issues can easily snowball. Misspellings, misplaced decimal points, miscategorization, or outdated entries lead to skewed insights and poor decisions. And in some sectors, like healthcare or finance, the consequences can be serious.
But data validation techniques are not just about preventing bad outcomes. They also support compliance, enhance automation, and keep marketing attribution honest.
Data validation examples
You’ve likely encountered data validation examples without knowing it. For example, when a customer fills out a form online, there’s a basic check to make sure the email field contains the “@” symbol and the phone number doesn’t include letters.
This small verification prevents incomplete or unusable entries from being saved in a database or sent to a sales team.
But the impact of validation goes far beyond web forms. It plays a central role in how data is used and trusted across different parts of a business. For instance:
- In marketing, a missing or incorrect UTM parameter can break campaign attribution, resulting in misleading performance data.
- In finance, a misplaced decimal in a billing field can trigger incorrect charges or revenue misreporting.
- In healthcare, an inaccurate patient ID might connect a patient to the wrong record, putting care and privacy compliance at risk.
Validation isn’t limited to user input, either. In server-side tracking setups, in which data moves automatically among systems, validation means that key parameters, like event names or timestamps, are formatted correctly.
If one tracking parameter is missing or mislabeled, it can cause errors that cascade through analytics reports, resulting in gaps or misattributed data.
Learn more about server-side tracking and tagging.
Why is data validation important?
Without validating data, you risk making decisions based on imperfect data that does not accurately represent the situation at hand. A single incorrect field can throw off attribution, trigger failed integrations, or cause financial losses due to miscalculated metrics.
But the value of data validation goes beyond preventing errors. Done well, data validation techniques help improve operational efficiency. It helps teams spend less time cleaning up bad data, fixing broken processes, or manually reviewing inconsistencies.
Data validation methods also support smoother integrations between and among systems. When data is validated at the source, it moves cleanly through platforms and avoids mismatches or failed syncs.

For marketing and analytics purposes, customer data validation is what makes attribution reliable. It helps ensure conversions are tracked, customer journeys are recorded accurately, and segmentation is based on real behaviors, not assumptions, all of which directly improve campaign performance, reporting accuracy, and ROI visibility.
More broadly, validation supports data governance and privacy compliance. It enforces formatting standards, detects missing consent fields, and reduces the risk of storing invalid or sensitive data. This helps businesses meet legal obligations and maintain user trust.
Ultimately, validated data is more than just “clean.” It’s trustworthy.
Types of data validation
There are many types of data validation. Most data validation procedures will perform one or more of the following checks to verify that data is correct before storing it in the database.
These are some common types of data validation checks.
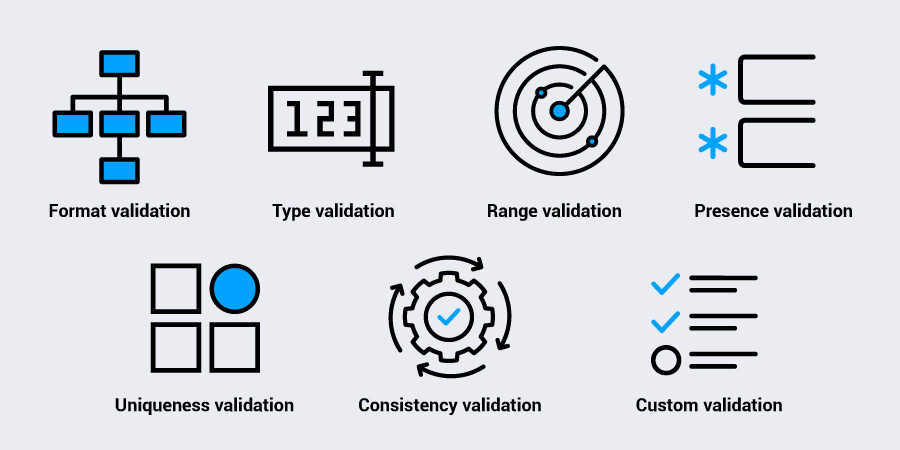
Format validation
This involves checks for whether a value follows a predefined pattern. For instance, an email address must include a domain, or a credit card number must follow a set numeric structure. Inputs must meet structural expectations before being processed.
Type validation
This confirms that a value is the expected data type, like an integer, a string, Boolean, or a date. If a system expects a number and gets a string of text, the validation fails. This prevents processing errors and type mismatches during calculations or data transformations.
Range validation
This helps to ensure that numeric or date values fall within set boundaries. If a score must be between 0 and 100, for instance, or an invoice date can’t be in the future, this check enforces those rules.
Presence validation
These checks make sure a field isn’t empty. This is critical for required fields, like user IDs, transaction amounts, or consent flags, where missing data renders the record incomplete.
Uniqueness validation
These checks verify that entries aren’t duplicated when they shouldn’t be. For instance, email addresses used for account creation should be unique. Duplicates can distort analytics, affect system performance, or trigger privacy risks.
Consistency validation
These checks look at how data fields relate to each other. For example, a user’s signup date shouldn’t be after their first login. These checks help detect logic issues across fields that appear acceptable in isolation.
Custom validation
These checks enable organizations to apply specific business logic that doesn’t fall under standard checks. For example, an internal rule might require that a sales region code is only used when the product type is ‘enterprise.’ These validations reflect internal processes and policy needs.
These categories are the structure that supports how data is vetted before use. In practical terms, they help ensure systems are working with valid inputs, so that decisions, automations, and reporting aren’t built on a faulty foundation.
Data validation techniques
While validation types define what is being checked, techniques determine how the checking happens. Let’s look at some of the most common data validation techniques.

Null and presence checks
Above all else, some fields just need to be filled in. Null validation is the process of checking for missing values, whether intentional (e.g. optional fields left blank) or accidental (e.g. a form error or system failure).
Presence checks prevent incomplete records from going unnoticed. They’re usually the first layer of validation, often coupled with more advanced techniques.
Rule-based validation
One of the simplest and most common techniques, rule-based validation, applies static logic to a field or set of fields. For example, it could apply the rule: “If field A is empty, mark the record as invalid.” Rules like this one are often defined directly within code or configured in form builders, CRMs, or data pipelines.
These rules are quick and easy to implement, and work well for clearly defined requirements. However, their simplicity can be a limitation in more complex environments.
Regular expressions (regex)
Regex is used to validate patterns in text. It’s ideal for checking structured inputs like email addresses, postal codes, social security numbers, or dates. A single regex pattern can determine whether a field matches the format it’s supposed to follow.
While flexible and powerful, regex patterns can be difficult to write and debug. They require precision because slight errors in the expression can result in valid entries being rejected or invalid ones passing through unnoticed.
Lookup validation
Instead of checking a value against a format, this technique validates it against a reference list or external source. For example, a product SKU entered into an order form might be validated by looking it up in the product database. If no match is found, the entry is flagged.
Lookup validation supports referential integrity and is commonly used when data is being entered across systems or needs to align with a master record.
Cross-field validation
This technique looks at the relationships between multiple fields. For instance, a delivery date should not be earlier than the order date.
Cross-field validation can be more complex to implement, especially when working across multiple data tables or inputs, but it’s important for maintaining contextual correctness.
Range and boundary checks
Used primarily for numeric or date values, this technique verifies that entries fall within accepted ranges. For example, it could be used to validate that temperature sensor readings are between -50 and 150 degrees Celsius, or to ensure that the quantity of a product ordered is not a negative number.
These checks are critical in the many systems that rely on metrics or numerical thresholds, such as financial models, scientific data, or statistical reporting.
Conditional logic validation
This technique involves applying logic based on other values. For example, a condition could exist that states: “If the user selects ‘Yes’ for newsletter opt-in, then an email address must be provided.”
Conditional logic allows for dynamic validation rules that change based on user behavior or context. This is common in form design, workflow automation, and UI validation, as it helps to simplify forms while still promoting accuracy.
Statistical anomaly detection
In more advanced setups, machine learning or statistical models are used to detect outliers or irregular patterns in data. It’s useful for datasets that are too large or dynamic for manual or static validation rules to handle effectively.
This technique is especially valuable for fraud detection, error flagging in large datasets, or finding issues in telemetry data that rule-based systems might miss.
Checksums and hash validation
Used mostly in security and finance, checksums help ensure data integrity by using a calculated value that’s validated alongside the actual data. When data is received or processed, the system recalculates the checksum, and if it doesn’t match the expected value, the data is assumed to be corrupted or tampered with.
This technique is commonly seen with credit card numbers, barcodes, and serialized products. It doesn’t validate the content itself, but flags changes or errors during transmission or entry.
Data validation testing techniques
Data validation doesn’t end with writing rules; it continues with data validation testing techniques. Data validation testing maintains your data’s quality and integrity as it is transformed and moved from its source to its target destination.
There are three common data validation testing techniques: unit testing, integration testing, and regression testing.
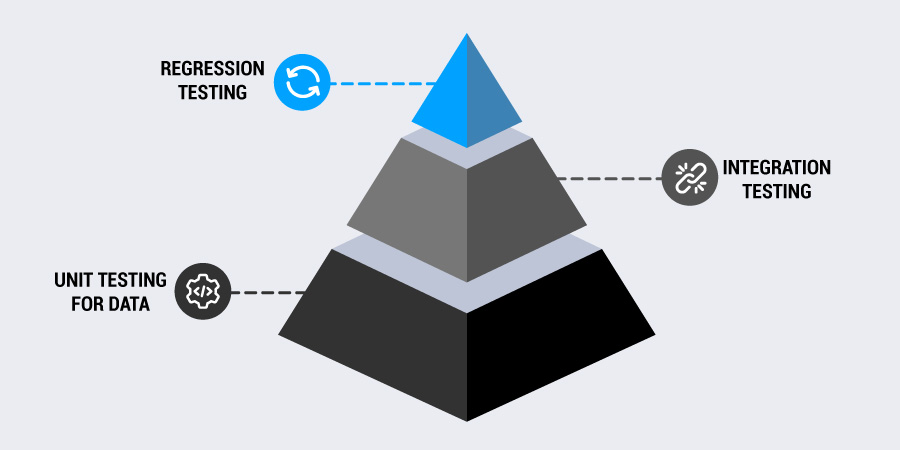
Unit testing for data
Just like with software, data logic benefits from unit tests, which are small, targeted tests that seek to ensure your transformation or ingestion steps handle specific inputs correctly.
For instance, if you’re parsing dates from various locales, a unit test can catch formatting edge cases before they corrupt the dataset.
Integration testing
Integration tests validate how different data systems work together. For instance, do your validation checks still hold when upstream systems change? Are your formats still aligned between the marketing platform and your CRM? These tests help spot disconnects between platforms before data enters production.
Regression testing
When validation logic evolves — for instance, if a new format is allowed or a rule is tightened — you need to make sure new checks don’t break valid, previously accepted data. Regression testing compares current results against historical “known good” data to promote stability.
Data validation checklist for ongoing accuracy
Data validation isn’t a one-time task. For consent data to be reliable and actionable, regular validation is essential. It helps ensure users’ choices are recorded accurately, stored securely, and respected across systems.
Here’s a quick checklist to help maintain data accuracy over time:
- Check consent status across systems: Compare records in your CMP, CRM, and analytics tools to spot inconsistencies.
- Verify storage integrity: Confirm consent records are stored securely and haven’t been lost or modified.
- Validate tag and script behavior: Make sure tags only fire when valid consent has been given.
- Test geolocation settings: Ensure region-specific rules (e.g. prior consent in the EU, opt-outs in the US) are working as intended.
- Review audit logs: Check that changes in consent are logged and traceable for accountability.
- Inspect UI display: Validate that banners and consent interfaces show correctly on all devices and browsers.
- Re-test third-party integrations: Confirm that consent signals are being passed correctly to connected tools.
Regular reviews like these help maintain trust, reduce privacy compliance risks, and ensure your data remains actionable.
Manual vs. automated data validation methods
Data validation techniques can be powerful, but they need the right delivery method to work consistently. That’s why it’s important to consider whether validation should be done manually or be automated.
Each approach has its place. Manual checks are valuable when you’re building new systems, auditing unexpected issues, or working with small, changing datasets. Automation, on the other hand, is critical for scale, as it applies the same logic reliably across large volumes of data and catches issues before they hit production.
In most setups, the most effective validation approach blends both.
Manual validation
Manual checks are most useful during early development, one-off audits, or when exploring unexpected behavior in new data sources. For example, you might spot-check daily campaign exports in a spreadsheet before loading them into a business intelligence (BI) tool.
Manual validation is particularly valuable for identifying anomalies that fall outside predefined rules. However, it doesn’t scale well. Manual validation is time-consuming, subject to error, and dependent on context that may not be documented.
Automated validation
Automated validation enables consistent, repeatable checks. Whether through SQL-based assertions, scheduled pipeline tests, or event stream monitors, automated validation helps flag critical issues early, often before data reaches production tools.
Common data validation tools
Choosing the right tools for data validation depends largely on your business’s architecture, scale, and specific data needs.
Some tools focus on validating static datasets in data warehouses, while others are built to handle real-time data streaming across distributed systems. In some cases, validation may be built into the transformation layer, while in others, it’s implemented as a separate monitoring process.
Rather than attempting to catalogue every tool on the market, it’s more helpful to consider what capabilities are most important for your use case, such as:
- Native support for your data platform
- Flexibility in writing rules
- Automated alerting
- Integration into your data workflows
- Privacy-respecting compliance features
At Usercentrics, our focus is on validation that protects user privacy while maintaining data quality. Our consent and server-side tracking infrastructure includes built-in validation to keep event data complete, compliant, and consistent across systems.
This includes safeguards against tag loss, validation of user consent signals, and the ability to surface gaps that may affect attribution or privacy compliance. These checks are designed to fit directly into the data flow to support both governance and performance.
Data validation best practices
Data validation techniques are not just about technical correctness. They’re about applying structured thinking to how data moves through your systems, and making sure that what enters and exits your pipelines reflects reality.
Here are some best practices to follow throughout your data validation lifecycle.
Validate at multiple points
Don’t rely on a single checkpoint to guarantee data quality. Apply validation where data enters your system, again during transformation, and once more before output or activation. This layered approach catches issues early and supports consistency throughout your workflow.
Align validation with real business needs
Effective validation targets the risks that matter. These could include missing consent data in a regulated environment, broken campaign parameters in analytics tracking, or malformed product codes that break ecommerce logic. Prioritize the rules that protect outcomes.
Maintain readable, traceable rules
Validation is a team activity. Rules should be clearly named, documented, and written, so collaborators and future maintainers can understand them at a glance. Include context in error messages so the person reviewing a failure can act without further investigation.
Log and monitor validation results
Validation shouldn’t stop bad data, it should teach you about your system. Monitor which rules fail most frequently, track recurring issues, and look for patterns. Logs offer visibility, and visibility creates opportunity for improvement.
Review and adapt
Your tech stack and the data you collect evolve, and so should your validation rules. Review them regularly to remove obsolete logic, tune thresholds, or respond to changes in data sources and business priorities.
Validate your data for better results
Validating data isn’t just a technical task; it’s a strategic one. Whether you’re preventing broken reports, enforcing consent requirements, or safeguarding business logic, the right data validation techniques protect your company’s performance and trust.
Plus, understanding the types of data validation checks, choosing the right methods, and following data validation best practices comes with multiple benefits. Your teams can reduce risk, improve efficiency, and make better decisions based on data that’s clean, complete, and compliant from the start.