

The purpose of this article is to give you a rough overview of BigQuery and a few insights into its pricing factors. Even though you might want to start immediately — trust me, I really understand you here — it is always recommended first to check out the pricing of the service one wants to use to verify that it fits your needs. I mean, none of us wants to suddenly wake up and see a $100k bill from his cloud provider since we didn’t understand the pricing model, right? Unfortunately, there are more than enough actual cases where this happened to people.
BigQuery in a nutshell
Google BigQuery is a serverless, highly scalable, and cost-effective, fully managed enterprise data warehouse used for easy and fast analysis of petabytes of data and billions of rows using ANSI SQL.
What does that mean for you?
- No server maintenance or configuration
- Automatic scaling to infinity
- The only responsibility is the creation/maintenance of tables and data
- In case you are familiar with the very popular ANSI SQL, you are already ready to start
→ It’s easy to get started.
In super simple terms
With BigQuery, Google offers a managed relational database with a pay-as-you-go model, only billing you for its service’s actual usage.
Furthermore, one additional advantage of BigQuery is that it integrates effortlessly with other GCP products. Also, you can easily visualize data from BigQuery in Google’s Data Studio.
You can do the whole interaction with BigQuery in several ways.
- Using the GCP console
- Using CLI commands
- Client libraries for the programming language of your choice
The costs
Starting directly with the costs might be a bit unusual. But especially in the cloud environment, costs are an essential factor and already helps in many cases if certain cloud technologies are even feasible for the intended use case or the use case will make costs explode.
Using BigQuery, you must factor in three different cost drivers.
- Storage costs (active vs long-term)
- Insert costs (batch vs streaming)
- Query costs (pay-as-you-go vs flat-rate pricing)
Storage costs
Typical for cloud services, Google bills you for the actual storage you use in BigQuery. Especially since there is a 10 GB free storage per month, you won’t have to fear any high bill when you want to start slowly with BigQuery. Google will charge any additional active storage in the case of multi-region US or EU by $0.020 per GB per month.
Now super “smart” people could say:
“Okay, then I will load my petabytes of data to BigQuery, do all my analyzing stuff, and then I delete it, and then I pay almost nothing. Since I don’t have any data there at the end of the month!”
Excellent idea, won’t work. Of course, Google is super intelligent and similar to all other serverless products; they check your storage usage in BigQuery every second and granular bill by second.
Compared to active storage, long-term storage, on the other hand, costs only 50% of the active one, so $0.010 per GB per month, as of today. It’s always recommended to structure one’s data for long-term storage to reduce costs.
But what is long-term storage in the first place, and how can one get it?
Long-term storage
Long-term storage in BigQuery is nothing one can book at GCP. It is something that Google automatically categorizes as such, depending on a simple factor.
When a table or table partition — we will handle table partitions in a later article — isn’t modified for 90 consecutive days, Google will automatically categorize it as long-term storage.
The actions defined as “modification” are pretty straightforward. Every write/insert of data into the table is a modification and reset the 90 days timer. Actions like querying, copying, or exporting data from the table and updating the table resource — not the data in it! — are considered “non-modifications” and, as such, won’t reset the timer.
Moreover, an important aspect to mention here is that long-term storage doesn’t imply any performance degradation, durability, availability, or other functionality. Google only charges you less for it.
We will discuss an approach to structure data to use the long-term storage functionality in detail in a later article.
Ways to insert data and its costs
In BigQuery, there are two possible ways to load data into your tables.
- Batch loading
- Streaming
With batch loading, you are using one big batch operation to load all the data into your BigQuery tables. Typical use cases here are importing CSV files, an external database, or a fixed set of log files.
On the other hand, the streaming approach lets you insert one record or small batches of records dynamically in your BigQuery tables. A typical use case here is when your servers directly write logs or user interactions — e.g., tracking — straight to your BigQuery without a step in-between.
Using the shared slot pool with on-demand-pricing batch loading is free of charge. But streaming inserts aren’t free and are charged $0.010 per 200 MB (multi-region US or EU). Google treats each row you write with a minimum of 1 KB in size.
Query costs
The third cost source of BigQuery is when you query your data. With on-demand pricing, Google bills $5.00 per TB — $0.000000000005 per byte — processed by your queries, even though there is a free tier of 1 TB per month.
Google calculates the total size of the charged data query costs by the columns selected and its column data type times the found values.
Example:
Imagine the following table being the BigQuery table you want to run a query against, while the first row outlines the data types for the individual column. This example doesn’t show the column names.

TYPE TABLE
As you can see in the above table, an INT64 and FLOAT64 data type count as 8 bytes, the BOOL one as 2. Besides these, Google treats NULL values as 0 bytes, so there are no additional costs for NULL values. To see the complete list of types and their billed size, you can visit the official BigQuery Pricing Docs.
So put together, if you query all the columns in the above table, it would cost you:
- Row #1: 2x 8 bytes, 1x 2 bytes
- Row #2: 1x 8 bytes, 1x 0 bytes, 1x 2 bytes
- Total: 28 bytes (→ $0.00000000014)
Of course, a total of 28 bytes is super low, and you can run endless queries till you reach the first free 1 TB, but usually, a table would be bigger than just two rows and three columns. Besides that, it’s also important to mention that regardless of how big the table is, Google defines a minimum of 10 MB per query.
Even if the table is only 5 MB — or 28 bytes in the above example — using 10 MB as a minimum cost per query results in a minimum of $0.00005 per query, which is still pretty low.
Another hack some people might think of is to use “LIMIT” in the SQL query so that BigQuery will return fewer data. Even though that will not affect the billing because BigQuery bills the bytes read in the query and not by the results returned.
Check out our whitepaper to learn more about strategies to optimize opt-ins while maintaining data compliance.
Going big
If you get huge and plan to store more than 1 PB of data in BigQuery, Google suggests reaching out to their sales representative, so there is for sure a way to get the rates down even further.
But what do I mean by “get huge”? Let’s have a quick look at GCP’s pricing calculator, and let’s see what 1 PB of data (active storage) would cost with BigQuer:
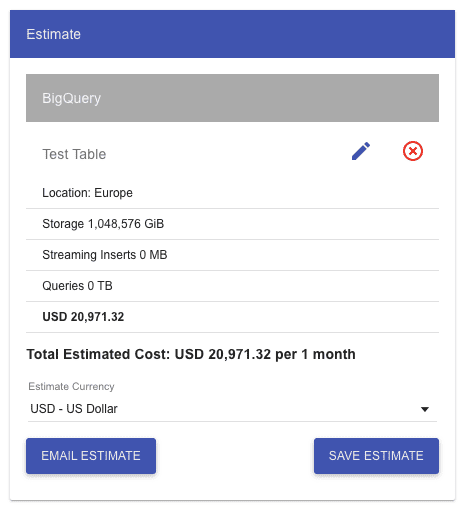
PRICING CALCULATOR
As you can see, only the storage without any inserts or queries would cost over $20k per month! Furthermore, I think that is high enough to negotiate the pricing with Google, especially since BigQuery will most likely not be your only high cost on GCP in this case.
In the following articles, we will see how to get started with Google’s BigQuery, based on an empty GCP project where we programmatically create new tables, fill them with our data and run queries against them.
Author
Pascal Zwikirsch
Pascal Zwikirsch is a Technical Team Lead at Usercentrics. He manages a cross-functional team of several frontend and backend developers while providing a seamless connection between the technical world and the product managers and stakeholders.
Pascal was a former frontend developer for several years and now specializes in backend services, cloud architectures, and DevOps principles. He experienced both worlds in detail. This experience and the collaboration with product managers made him capable of constructing full-fledged scalable software.
Besides his job as a Team Lead of the B2B developer team, he likes to share his in-depth knowledge and insights in articles he creates as an independent technical writer.
If you have any questions or additions, feel free to hit me up on LinkedIn to get in contact with me.

Join our growing community of data privacy enthusiasts now. Subscribe to the Usercentrics newsletter and get the latest updates right in your inbox.



